Movie Recommender System
Introduction
Data shows high turnover rates between users and their choice of streaming platforms; meaning one bad recommendation and we may lose them as a customer. Our goal is to minimize these turnover rates by instilling trust through consistent and precise recommendations. Our approach will be to maximize precision by optimizing the choice of algorithms, evaluation schema methods, and parameters. This will be done using exploratory analysis and by evaluating a series of different models.
Exploratory Data Analysis
The data we are working with includes 943 users and 1,664 movies. The data contains a lot of users and movies with a low rating count, meaning they will not provide much feedback for our model and are considered noise. By removing movies with less than 50 ratings and users that haven't rated over 95 movies our dimensions reduce from 943x1664 to 369x691.
Train/Test
Three methods were used for splitting the data. These are methods from the recommenderlab library in R. The methods were a normal split, cross-validation and bootstrap. The split takes a fixed 80% and 20% for the train and test sets respectively. Cross-validationuses k-fold validation sets, in our case we set k equal to four and the train/test sets were 75% and 25% respectively. Lastly the bootstrapping method samples the rows with replacement which allows us to sample on user more than once. For the bootstrap method the train and test set sizes were 80% and 44% respectively.
Modeling
Next we will use different algorithms with different parameters to optimize model performance. The algorithms will include:
-IBCF using Cosine
-IBCF using Pearson
-UBCF using Cosine
-UBCF using Pearson
-SVD
-Random (Our baseline)
All model performances will be compared with our random algorithm which is the baseline for model performance. The performance for each model will be compared with one another, and overall performance will be compared between the different evaluation scheme methods described earlier.
Results
The three different train/test methods results in the same thing. Our SVD algorithm showed the greatest AUC for each method. Below you can see one of the examples which is from the boostrap method. It's important to note that UBCF Pearson performed almost just as well as SVD.
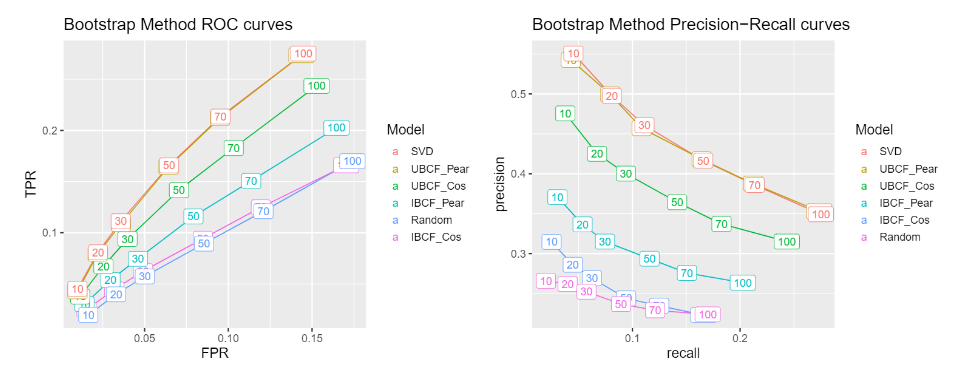
Conclusion
To reiterate, our goal is to maximize precision in order to reduce customer turnover rates. We performed exploratory analysis, split the data using three different evaluation schema methods, created six different models for each schema, and plotted our results. In conclusion, by using User-Based Collaborative Filtering with the pearson method we can maximize precision and minimize customer turnover rates.
Special thanks to Paul Perez for teaming up with me to create this project.Github Repository