Amazon Music Recommendations
Introduction
The goal of this project is to produce reliable recommendations at an efficient rate using a relatively large dataset (>1M ratings). Specifically we want to recommend music based off Amazon music reviews using Python, PySpark, and Alternating Least Squares (ALS) method.
The dataset was obtained from one of Amazon's Customer Review datasets (https://s3.amazonaws.com/amazon-reviews-pds/). Amazon provides a small sample of customer evaluations in order to help further research in a variety of disciplines, in our case we built an ALS model using Pyspark to recommend music for a large sum of individuals. The data contains reviews spanning from 1995 to 2015 in the form of ratings (1-5 stars).
Exploratory Data Analysis
Amazon's customer digital music review dataset is loaded as a tsv (tab-separated values) file using pandas and it has 1,681,484 rows and 15 columns. Out of the 15 columns we will be focused on the customer ID, product ID, product title and star rating.
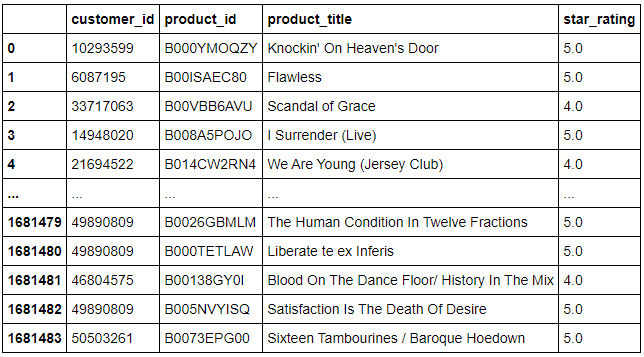
There are close to 700k unique songs and 800k unique users which need to be filtered according to activity.
Building The Model
A little over 10k of the most active users and the 10k most rated songs were used in order to train the model. This mean we were dealing with a user-item matrix with over 1,000,000 ratings, next we store our dataframe in pyspark.

For ALS to work with Pyspark we must create numeric values for the customer and product ID's. We do this by taking their respective index values and applying those to be their new ID.
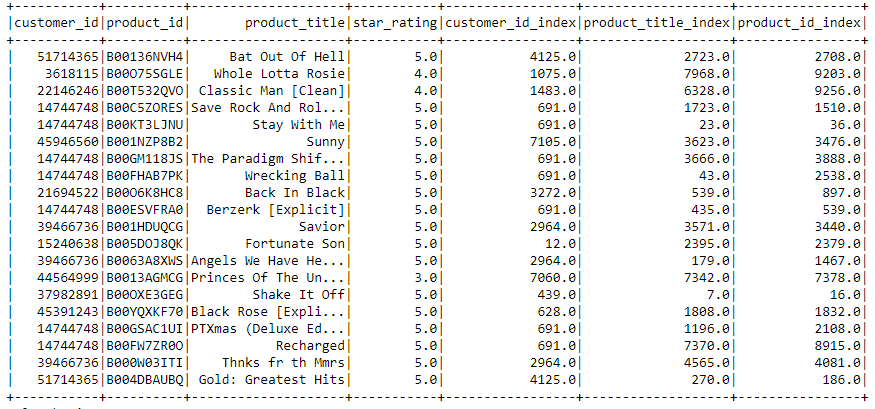
We randomly split our dataframe into 80/20 train/test sets. We create the ALS model by passing through the following parameters that we know; new customer and product ID, star rating, coldStartStrategy=drop and nonnegative=True. This way we do not predict negative values. Next we experimented with parameters which includes the rank, max iterations, and regularization parameter in order to minimize RMSE. The algorithm with the best results can be seen below.

Results
Our model had an RMSE of 0.972 and we can view the rating predictions below.
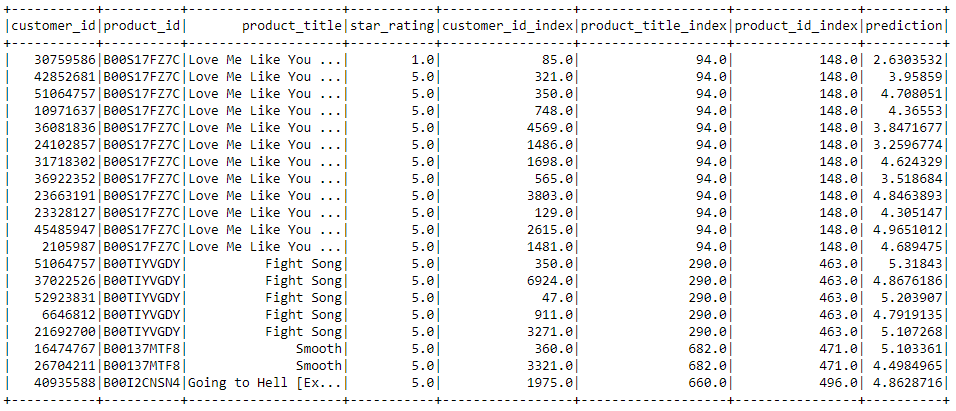
The total time it took to create five song recommendations for 10k songs using the PySpark ALS Model was just over two minutes. Lastly the song names and index IDs were matched so that song names were returned from each recommendation rather than the index ID. Below you can see the five recomendations made for the song 'Endless Love'.
 Special thanks to Paul Perez for teaming up with me to create this project.
Special thanks to Paul Perez for teaming up with me to create this project.Github Repository